Publications
2024
-
 Exploration and Mitigation of Gender Bias in Word Embeddings from Transformer-based Language ModelsA. Hossain, K. M. A. Hannan, R. Haque, H. Musarrat, and 4 more authors2024Manuscript submitted for publication
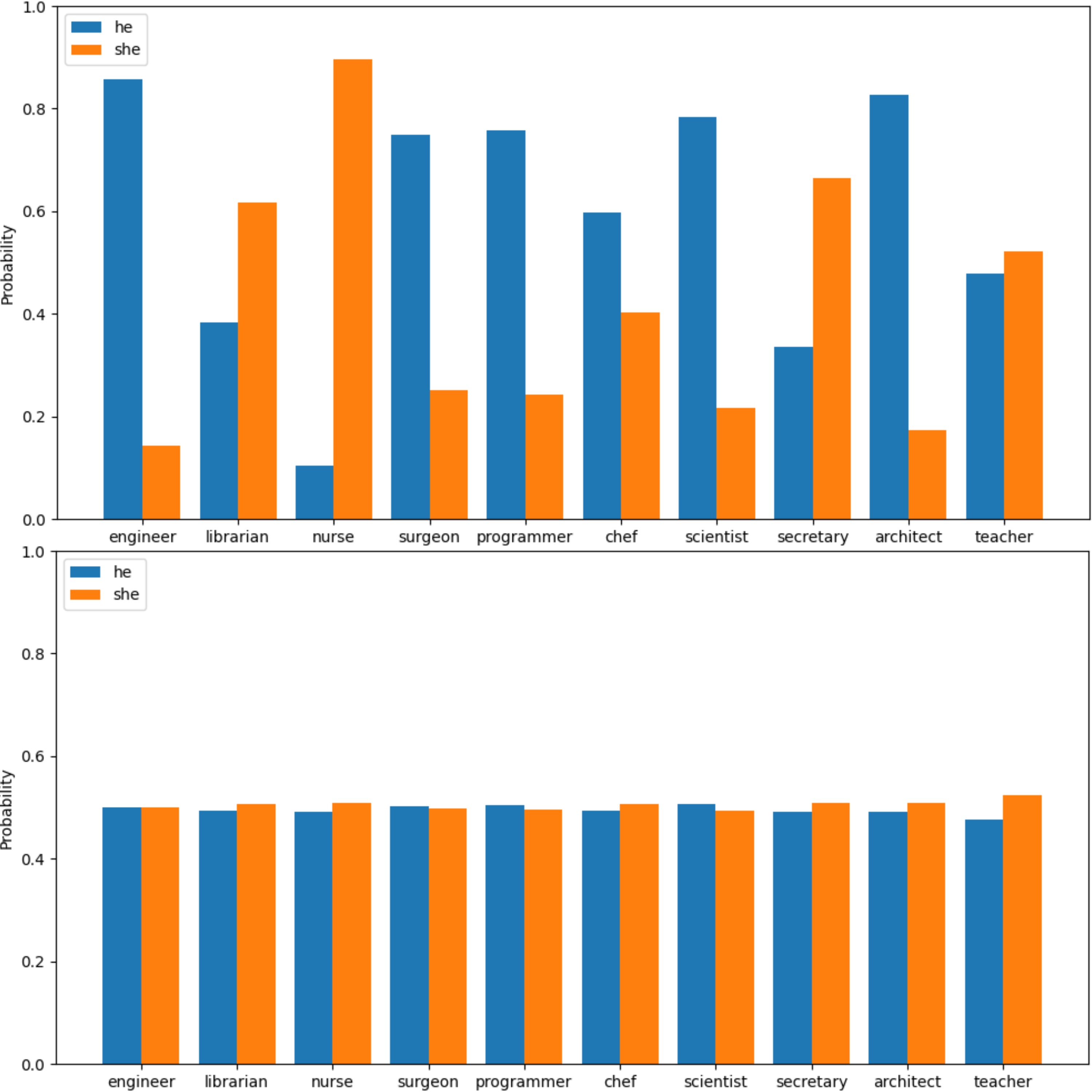
Exploration and Mitigation of Gender Bias in Word Embeddings from Transformer-based Language ModelsA. Hossain, K. M. A. Hannan, R. Haque, H. Musarrat, and 4 more authors2024Manuscript submitted for publicationMachine learning can uncover data biases resulting from human error when implemented without proper restraint. However, this complexity often arises from word embedding, a prominent technique for capturing textual input as vectors applied in different machine learning and natural language processing tasks. Word embeddings are biased because they are trained on text data, which frequently incorporates prejudice and bias from society. These biases may become deeply established in the embeddings, producing unfair or biased results in AI applications. Efforts are made to recognize and lessen certain prejudices, but comprehensive bias elimination is still tricky. In Natural Language Processing (NLP) systems, contextualized word embeddings are now more commonly used for representing texts than traditional embeddings. It is also critical to evaluate biases contained in these since biases of various kinds have already been discovered in standard word embeddings. We focus on transformer-based language models including BERT, ALBERT, RoBERTa and DistilBERT which produce contextual word embeddings. To measure the extent to which gender biases exist, we calculate the probabilities of filling MASK by the models and based on this, we develop a novel metric, MALoR, to measure gender bias. We then continue pretraining these models on a gender-balanced dataset to mitigate the bias. Gender balanced dataset is created by applying Counterfactual Data Augmentation (CDA). To ensure consistency, we perform our experiments on different gender pronouns and nouns - “he-she,” “his-her,” and “male names-female names.” Finally, using a downstream task, we verify that our debiased models show no performance drop. These debiased models can then be used across several applications.
@misc{hossain2023exploration, title = {Exploration and Mitigation of Gender Bias in Word Embeddings from Transformer-based Language Models}, author = {Hossain, A. and Hannan, K. M. A. and Haque, R. and Musarrat, H. and Rafa, N. T. and Islam, S. B. and Dipu, S. A. and Sadeque, F. Y.}, year = {2024}, note = {Manuscript submitted for publication}, }
